Compiler Design : CourseIntro
2018년도 2학기 연세대학교 Compiler Design CourseIntro 수업내용이다
Compiler Design : CourseIntro
-
이전의 컴퓨터들
- 1940년대 처음으로 나온 전기적 컴퓨터는 굉장히 크고, 스위치와 카드 리더기로 만든 binary machine code 로 프로그램 되었다. 따라서 코드의 재사용이 불가능하고, 유지보수가 힘들었다.
- ‘버그’ 라는 말은 기계에 벌레가 들어가서 나타난 오류에서 파생되었다.
-
Assembly Languages
- 어셈블리 언어는 기계어 명령어를 상징적인 기호로 변환하여 기억하는 ‘니모닉’ 개념으로 표현하기 위해 발명되었다.
- 어셈블리 언어 코드와 기계어는 1대1 매칭이 된다. 따라서 번역하는데 직관적이다.
- Assembler 는 어셈블리 언어를 기계어로 변환해준다
- 기계어와 비교한 어셈블리 언어의 장점
- 니모닉은 인간이 이해하기 쉽다
- 프로그램을 재사용하고(같은 architecture 에서만!) 재배치할 수 있도록 해준다
- 어셈블러를 사용해서 기계어로 변환한다(수동변환보다 더 생산적이다)
- 매크로를 사용할 수 있다
- Inline assembly : 어플리케이션단의 high level language에 동작속도를 빠르게 하기 위해 assembly language를 적용한다
-
High-Level Languages
- 1950년대 FORTRAN(FORmula TRANslator) 의 발명으로 시작되었다
- 컴파일러는 기계에 종속적이지 않은(machine-independent) 한 프로그램의 개발을 가능하게 했다. 또는 hardware independent 하다고 한다.
-
Compilation
- 컴파일러는 high-level 프로그램을 목표 프로그램의 기계어로 변환시켜준다.
- 컴파일러는 프로그램이 잘못되었는지 판단할 수 있다.
- 컴파일러는 맞는 효과적인 코드를 만든다.
- 컴파일러는 나중에 사용자가 목표 프로그램을 돌릴 수 있게 해준다.
- compilation 은 두개의 부분으로 나누어진다
- Analysis 단계 : 소스코드에 표현될 명령을 선택한다. 각각의 명령들은 트리구조로 기록된다.
- Synthesis 단계 : 트리구조를 받아서 명령을 타겟 프로그램으로 변환한다.
platform X : 어떤 OS든 + 어떤 하드웨어이든을 지칭
-
컴파일러 구조
Source Code -> Lexical Analyzer -> Syntax Analyzer -> Semantic Analyzer -> Intermediate Code Generator // 여기까지가 Compiler Frontend (Analysis 단계)
-> Code Optimizer -> Code Generator -> Target Assembly Program // Compiler Backend(Synthesis 단계)
Lexical Analysis (토큰화)
-
Scanner에 의해 이루어진다.
-
CHARACTER들을 토큰으로 바꾼다.
-
lexeme이란 해당 토큰의 스트링 이름이다.
ex) <id,1> 의 lexeme은 “position”
-
Scanner는 공백과 주석을 없앤다.
-
Scanner는 문법적 오류나 토큰형성에 문제가 되는 부분을 에러낸다.
Syntax Analysis (문법적 오류 체크)
-
Parser 에 의해 이루어진다.
토큰을 AST로 정리한다.
-
문법은 Context-free grammer(CFG)로 정의된다.
CFG는 AST의 구조를 정의한다.
-
Parser는 AST가 생성되지 않으면 syntax error 를 생성한다.
이런 오류있는 프로그램은 CFG에 맞지 않는다.
Semantic Analysis (의미 체크)
-
AST를 분석함으로서 프로그램의 의미를 분석한다.(Consistency check)
-
Static semantic checks(compile time)
- identifier가 사용되기 전에 정의되어있는지
- identifier가 부적절하게 사용된 경우(함수의 이름, 형변환)
- 함수의 argument 체크
- type checking (a[2.6],int2float)
-
Static semantic check 의 예시
if(a+b) {} int a; a("hi"); 10("hi"); "hi" + 77; void foo(int a, int b); foo(1); -
Dynamic semantic checks(run-time)
- bound를 벗어난 array
- division by zero
-
Dynamic semantic check 의 예시
b = readline(); if(b==0) raise ERROR; //run time check x = a/b; -
Dynamic semantic check(run-time) Problems
- It requires additional checks -> overhead(SLOW)
- Size of program increases(Bigger)
-
-
Semantic check 를 실패하면 semantic error 이다
-
프로그램의 의미를 분석해서 Decorated AST 를 배출한다.
AST의 형이나 식의 의미를 담은 것이 Decorated AST
ex) X + Y 의 operand type
여기까지의 단계가 Compiler Frontend (high level)
Intermediate Code Generation (AST -> IR)
- AST를 IR로 변환한다.
- IR 은 기계 지시어로 바꾸는 변환을 쉽게 한다.
- IR 디자인의 사소한 결정이 컴파일러의 속도나 효율에 크게 타격을 줄 수 있다.
- Popular IRs : ASTs(GCC), Directed acyclic graphs(DAGs), Three address code(3AC), Static single assignment form = SSA (GCC)
Code Optimization (메모리,효율 증가)
-
Code optimizer가 하는일
-
IR을 분석하고 향상시킨다.
-
실행속도, 파워 소모량, footprint의 감소
footprint 란 차지하는 메모리나 효율을 의미한다.
-
기초 semantic은 반드시 유지한다.
-
-
대표적인 optimizations
- 상수를 계산한다. (Constant Propagation)
- 쓸모없거나 도달할 수 없는 코드 삭제 (Dead code elimination)
- 덜 자주 실행되는 곳으로 계산코드를 옮김 (Move to out of a loop body)


Code Generation (기계어 생성)
- 타겟 코드를 만들어낸다
- 각 IR instruction 마다 타겟 instruction 을 선택한다
- 프로그램의 각 부분마다 레지스터에 어떤 변수를 저장할지 결정한다
- 레지스터의 개수는 변수의 개수에 비해 제한되어있기 때문에 어떤 변수를 레지스터에 저장할지는 중요한 요소이다.
Compiler Phases, Theory and Tools
- Lexical analysis : REs(regular expressions), scanner tools
- Syntax analysis : parser tools
- Semantic analysis : type checking, this is not generator (not automatic)
- Code optimizations : doing sophisticated analysis for optimizations (data-flow engines, LLVM framework) <- this is not compiler, this is tools
- Code generation : equally complicated (automatic code generators)
Error Detection, Error Reporting and Recovery
If compiler finds error, generates the below error
-
Lexical errors
“abc //unterminated string
-
Syntax errors
a + (2*b //parenthesis
-
Semantic errors
variable not defined(delcared)
컴파일러는 에러가 난 위치를 정확하게 보고해야 한다.
에러를 탐지한 후 컴파일러는 복구하고 진행할 수도 있다.(멈추지 않고 계속 에러가 있는지 찾는다)
Error recovery : all error find -> fix all -> recompile (not 1 to 1)
Error recovery is optional with the compiler project of this course
JVM & Java Bytecode Primer
-
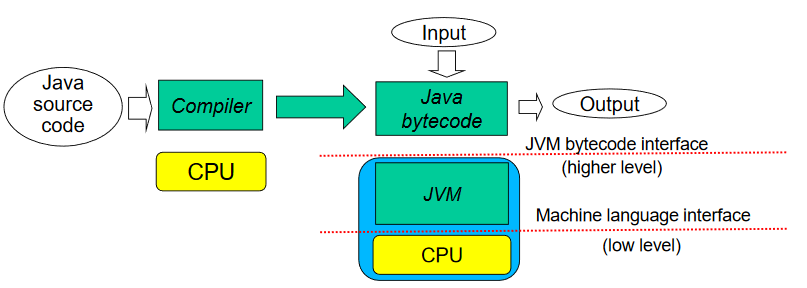
JVM
Java bytecode를 분석하는 processor 라고 이해 (사실 program)
이 프로그램의 목적은 OS 위에서 Java bytecode 를 분석하는것
own instruction set, construction set 을 가짐 (마치 processor처럼)
higher abstraction level 이라고 함. (CPU는 low abstraction level)
=> java exception, java garbage collection 등을 가지므로 higher abstraction level 이다.
-
Compiler : Java bytecode를 생성하는 역할
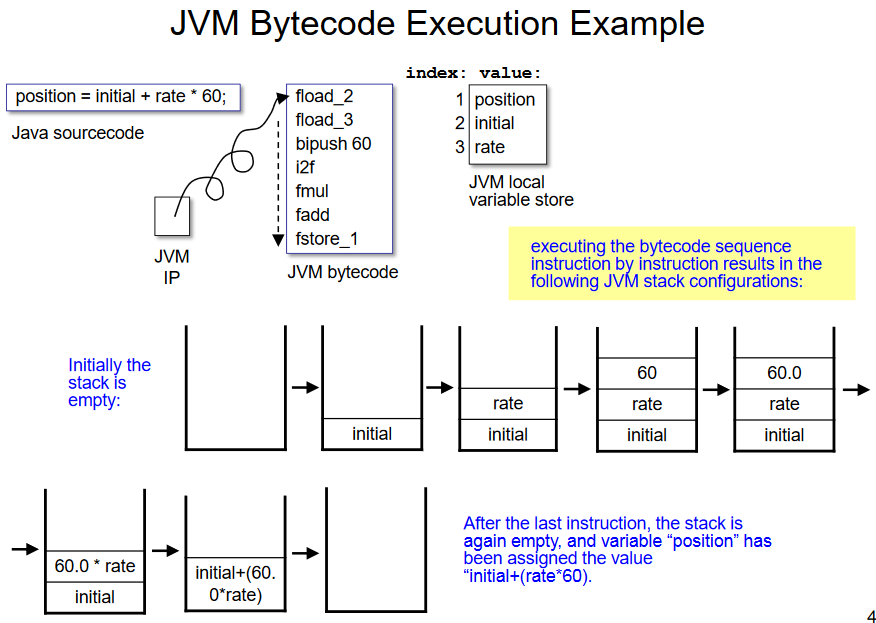
JVM Stack and Instruction Set
fload_<n> // load instruction. float value is on to the stack
fstore_<n> // store instruction. float value is poped and store it in local variable
i2f // take int convert to float (topmost stack-element)
bipush // push byte value onto the stack
fmul // perform floating point multiplication of the topmost stack elements,push the result onto the stack
fadd // compute the sum of the two topmost stack elements, push the result onto the stack.
These instructions run on JVM
- JVM IP (instruction pointer) : initially points to 0, increment
- JVM no need to use registers, use stack.
- Argument 는 stack 에 저장된다.
Q. 왜 JVM은 stack based 를 사용하는가?
A. real processor는 register가 있고, JVM은 stack을 사용하므로 완벽하게 맞지 않는다. 어플리케이션의 performance penalty 라고 볼 수 있다(CPU와 비교하여). stack code is smaller than register code (not many operands),
Comments