Database Basic Concept
Database Definition
컴퓨터의 활용 범위가 확대됨에 따라 모든 분야에서 사용하는 관계된 데이터들의 집합
데이터란 알려진, 또는 기록된 사실들
책의 한 페이지, 명함 등
Implicit properties of database
Universe of Discourse (UoD) : mini-world
고유의 의미를 가지고 논리적으로 결합된 데이터의 모임이다.
특정한 목적을 위해 설계, 구현되었다.
어떤 사이즈나 복잡도에 상관없이 구현이 가능하다
DBMS의 정의
데이터베이스 관리 시스템(Database Management System) 이다.
-
Defining: 데이터의형, 구조, 제약조건 정의
-
Constructing: 저장 매체에 데이터를 저장
-
Manipulating: 특정한 데이터의 질의 및 검색
-
Sharing : 다양한 사용자들에게 동일한 데이터를 공유
Database System의 구조
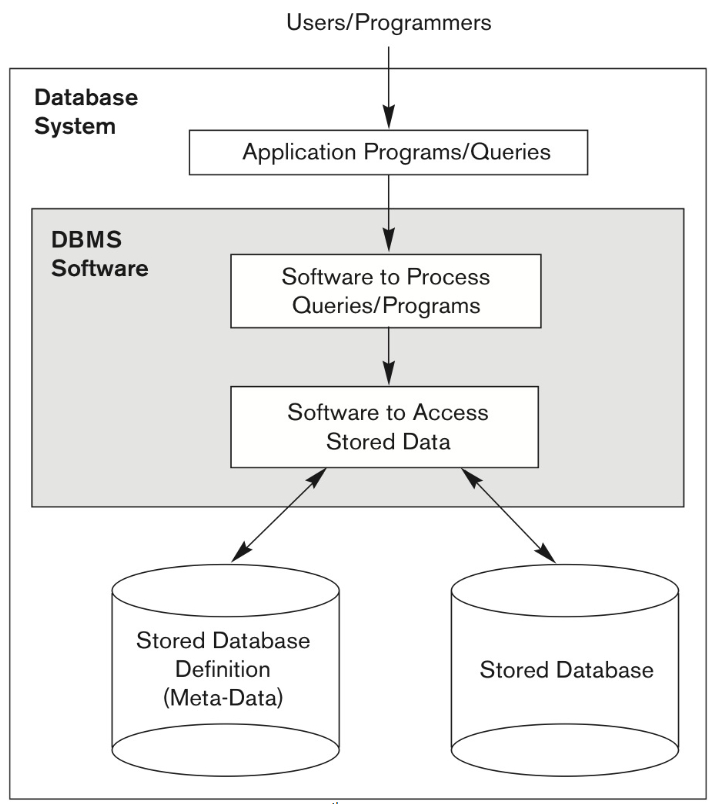
Database System 은 DBMS 보다 더 포괄적인 구조이다. (즉 DBMS는 안에 포함된 개념)
User 가 접하는 Application Programs/Queries 를 통해 DBMS에 접근하며 DBMS 를 거쳐서 Stored Database Definition (Meta-Data) 와 Stored Database 에 접근할 수 있다.
Database System = Application Program + DBMS + Stored Database Definition + Stored Database
DBMS는 여기서 중간자 역할을 하며 Queries/Programs 을 처리하는 소프트웨어와 Stored Data 에 접근하는 소프트웨어를 가지고 있다.
Defining
레코드의 구조를 정의한다. 레코드에 어떤 속성들이 들어가 있는지 정의한다.
데이터의 형을 정의한다. 각 속성들이 어떤 형을 가져야 하는지 정의한다. (coding scheme, 사용자 정의에 따라 정의할 수도 있다.)
Constructing
데이터를 저장하는 작업이다.
Manipulating
검색, 갱신, 첨가, 삭제를 할 수 있다.
Sharing
접근할 수 있는 사용자들끼리 공유할 수 있다.
File system vs Database
파일 시스템은 많은 동일한 데이터를 중복해서 별도로 관리하기 때문에 저장공간과 관리 노력에 있어서 비효율적이다. 데이터베이스는 이러한 중복을 줄이고 동시에 공유하게 할 수 있다.
DB 접근의 특징
한마디로 데이터 추상화가 가능하기 때문에 사용한다.(데이터를 쉽게 재사용한다)
-
Self-describing nature of database system
DB 의 정의와 DB 그 자체를 포함하고 있다.
catalog(meta-data) 란 File들의 구조, 데이터의 형, 제약조건을 담고 있다.
반대로 파일 시스템에서는 응용프로그램에서 데이터의 정의가 이루어져야 한다.(application-dependent) 그리고 데이터의 정의는 프로그램간 공유가 불가능하다.
-
Insulation between Programs and Data, and Data Abstraction
데이터 구조가 catalog 에 저장되어 독립적으로 관리되므로 program-data independence의 특징을 가진다.
DB 접근은 program-operation independence 를 object-oriented DBMS 로 구현할 수 있다.
DB 접근은 data abstraction 을 통해 직접 데이터를 표현하지 않고 개념적으로 표현할 수 있다. OODB/ORDB 에서는 데이터의 구조와 연산을 추상화할 수도 있다.
반대로 파일 시스템에서는 데이터의 구조가 프로그램에 종속적이므로 데이터 구조가 변경되면 프로그램을 변경해야 하고 program-operation independence 가 불가능하며 data abstraction 도 불가능하다.
-
Support of Multiple Views of the Data
특정 데이터의 view 를 만들어서 보여줄 수 있다.
-
Sharing of Data and multiuser transaction processing
Online Transaction Processing(OLPT) 가 가능하다.
Transaction 이란 프로그램을 실행하거나 프로세스를 실행하는 하나 이상의 데이터베이스 접근을 의미한다.
Concurrency Control 이 가능하다. 동시에 접근시 그것을 관리하는 것.
Database System의 사용자들
크게 Front 와 Behind 로 나뉜다.
Front : DBA, DB designer, End user, System analysist and application programmers
Behind : DBMS system designer and implementers, Tool developer, Operators and maintenance personnel.
DBA는 Database Administrator 로 데이터베이스의 사용을 허가하고(보안유지를 담당), 데이터베이스의 현황과 성능을 감시하고(성능 관리), S/W & H/W 를 관리한다.
DB designer 는 데이터의 정의와 저장구조를 설계한다. 이 과정에서 DB 사용자의 요구사항을 조사하고 이해한다. View 를 활용하는 사용자이다.
End user는 일반적으로 데이터베이스를 사용하는 사람이다. casual end user는 DB 사용빈도수가 적지만 다양하고 복잡한 정보를 원하는 중급/고급 관리자이다. naive, parametric end user는 정형화된 질의/갱신 작업을 반복적으로 수행하는 은행이나 예약시스템을 쓰는 사용자이다. sophisticated end user는 데이터에 복잡한 작업을 수행하는 엔지니어나 과학자, 사업분석가 등이다. stand-alone user는 개인 데이터베이스 사용자이다.
canned transaction : 정형화된 질의 갱신 작업
System analysts and application programmer는 사용자의 요구사항을 분석하는 시스템분석가(canned transaction 을 설계) 와 canned transaction을 관리하기 위한 프로그래밍, 디버깅등을 행하는 응용프로그램 개발자가 있다.
DBMS 접근을 사용한 장점
-
Redundancy
데이터 저장공간을 공유해서 저장공간을 절약하고 데이터를 관리하는 노력을 감소시킨다.(데이터 갱신 일치)
반대로 file processing(파일 시스템) 은 동일한 데이터가 중복되어서 관리가 힘들고 동일 데이터를 갱신시 모두 다 갱신해 주어야 한다.
-
Authorized access
데이터 접근을 허가하는 관리가 이루어지므로 보안에 용이하다. Account privileged(read/write/function)
-
Persistent storage
파일을 처리하는데 DBMS는 변환과정을 자동으로 해준다.
-
Storage structure & search techniques
쿼리를 효율적으로 실행하게 해준다. Query processing optimization(index,buffering,caching) 을 수행한다. 물리적인 DB 디자인을 하고 수정하기도 한다.
-
Backup & Recovery
백업과 리커버리가 되어서 올바른 데이터가 유지된다.
-
Multiple User Interface
다양한 사용자 유형에게 다양한 인터페이스를 제공해서 숙련도를 지원한다.
casual user 에게는 query language, application programmer 에게는 programming language interface, naive user 에게는 form, stand-alone user 에게는 menu-driven, natural language 를 제공한다.
-
Represent complex relationship among data
데이터 사이의 복잡한 관계를 표현한다.
-
Enforcing integrity constraint (DB의 semantics)
DBMS에 의해서 데이터를 자동 점검한다.
-
Using Rules & Trigger
어떤 변화가 일어났을 때 trigger 를 주어 활성화되게 할 수 있다.
-
표준화
명칭이나 데이터 포맷이나 출력 포맷 등을 표준화할 수 있다.
-
응용프로그램 개발 시간의 단축
-
유동성
변화에 대처가 용이하고 기존 프로그램이나 데이터에 영향이 없다.
-
최신 데이터 이용 가능
많은 사용자 환경에서 concurrency control (은행, 예약) 을 수행한다.
-
경제성
DBMS 사용의 범위
DBMS를 사용하면 최초 투자 규모가 커지고 보안이나 concurrency control, recovery, integrity contraint checking 에서 overhead 가 많이 발생하기 때문에 함부로 사용해서는 효율적이지 못하다.
간단하고 바뀌지 않는 데이터들이나 실시간으로 요구되어야 하는 데이터나 embedded system 이나 다중 사용자가 접근할 일이 없는 데이터에는 DBMS를 사용하지 않는다.
Data model
데이터베이스의 구조를 보여주는데 사용되는 개념들의 집합이다.
데이터베이스의 구조는 데이터에 적용된 데이터타입, 관계, 그리고 제약조건이 있다.
-
Conceptual(High-level) data model
가장 보편화된 모습이며 DB 사용자가 이해하는 데이버이스의 구조이다. Entity-Relationship model 이 있다. 여기서 entity 는 실세계의 물건이나 개념에 해당하고 attribute 는 개체의 성질이나 속성, 관계는 둘 이상의 개체간의 관계이다.
-
Physical(low-level) data model
데이터가 저장된 모습이며 데이터의 저장방법을 기술하고 레코드 포맷과 순서를 보여준다. Access path 란 각 레코드를 찾아가는 포인터 구조를 말하며 Index 와 같다.
-
Implementation(Representation) data model
E-R Relationship을 기계가 이해하기에 더 편한 모습이다.(기계가 이해하고 있는 모습) 개념적 데이터 모델과 물리적 모델의 중간 모델이다. 물리적인 상세한 정보를 추상화하면서 데이터의 구조를 표현한다.
Relational data model, network data model, hierarchical data model, object data model
-
Self-describing data model
데이터안에 형과 식을 같이 넣는 모습이다.
ex) JSON, XML, Key-value stores & NOSQL 형식이다.
Database Schema
데이터가 어떻게 생겼는지 보여주는 데이터베이스에 대한 설명을 가지고 있다.
DBMS의 catalog 에 저장된다.
데이터베이스 설계 시 정의되며 자주 변경되지 않는다.
제한된 정보 표현을 한다 (데이터 타입이나 제약조건을 표현하지 않는다)
Meta-data : Database Schema + constraints
Schema diagram
스키마를 표현하는 그림이다.
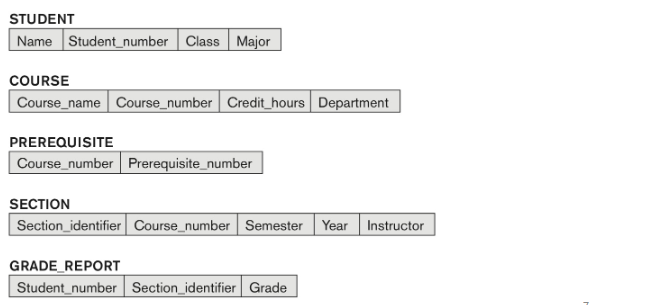
Schema construct : diagram 의 한 단위
Instance
저장된 데이터 그 자체를 의미한다.
Database state(snapshot)
특정 순간의 instance 들의 집합을 의미한다.
Define : Empty state
Populated(loaded) : initial state
Update operations : current state/valid state
DBMS는 데이터베이스의 상테가 변할 때마다 catalog 에 저장된 meta-data의 스키마/제약조건을 만족하는지 valid state 를 검사한다.
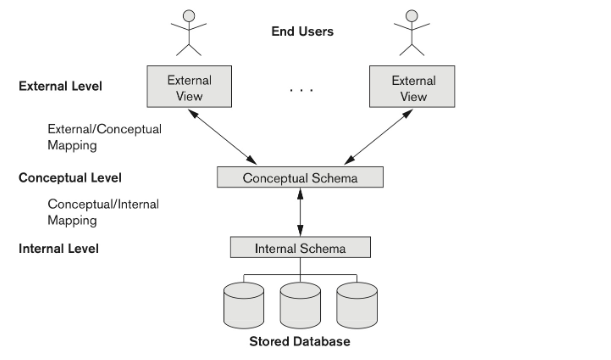
Three schema architecture
-
External(view) level : External schema (user view)
사용자 그룹의 목적에 따라서 데이터베이스의 일부분을 기술한다.
전체 데이터베이스의 형태나 데이터의 물리적 저장 구조는 숨겨진다.
Implementation data model 과 conceptual data model 을 사용한다.
-
Conceptual level : conceptual schema
사람이 이해하기 위한 전체 database의 구조를 묘사한다.
데이터의 물리적 저장 구조는 숨겨진다.
Entities, data types, relationships, user operations, constraints 들의 개념들을 표현한다.
Implementation data model 과 conceptual data model 을 사용한다.
-
Internal level : Internal(physical schema)
실 데이터가 저장되는 방법을 묘사한다.
데이터베이스의 물리적 저장 구조와 access path를 보여준다.
Physical(low-level) data model 을 사용한다.
-
예시(대학 database)
Physical schema 는 저장된 데이터들의 모습과 나타내는 index 를 보여준다
Conceptual schema 는 각 entity의 구조를 보여준다(제약조건,관계,데이터타입 등)
External schema 는 특정 view를 보여준다. (ex) course_info )
Mapping : 각 레벨들 사이의 요청이나 결과를 변환해주는 작업
Logical data independence : 응용프로그램이나 외부 스키마에 영향을 주지 않으면서 개념적 스키마를 독립적으로 변경이 가능하다.
Physical data independence : 외부/개념적 스키마에 영향을 주지 않으면서 내부 스키마를 독립적으로 고칠 수 있다. 응용프로그램에도 영향을 주지 않는다.
DBMS 언어
스키마 정의 언어
-
DDL (Data Definition Language)
개념적 스키마 및 매핑 정의
설계된 DB 구조를 DBMS catalog에 입력
Conceptual level 과 Internal level의 일부분(store)을 담당하고 있다
-
SDL (Storage Definition Language)
내부스키마 및 매핑을 정의한다. 요즘의 DBMS에서는 거의 없음
-
VDL (View Definition Language)
물리적으로 존재하는 스키마와 별개로 외부 사용자에게 뷰를 정의하는 언어
-
DML (Data Manipulation Language)
High-level DML 은 what to get 을 지향한다. non-procedural DML, set-at-a-time DML 등이 있다. ex) SQL
Low-level DML 은 how to get 을 지향한다. procedural DML, record-at-a-time DML. ex) GET NEXT
DBMS Interface
- DBA or DB designer : DDL, 권한 명령, 계정 생성
- Casual end user : menu-based, form-based, natural language, keyword-based, speech input and output interface 를 사용한다.
- Parametric end user : 특정 업무를 처리하기 위한 interface (은행원의 은행업무 interface)
- SW programmer & System analyst : DML을 임베디드 환경에서 사용한다.
DBMS Component Modules
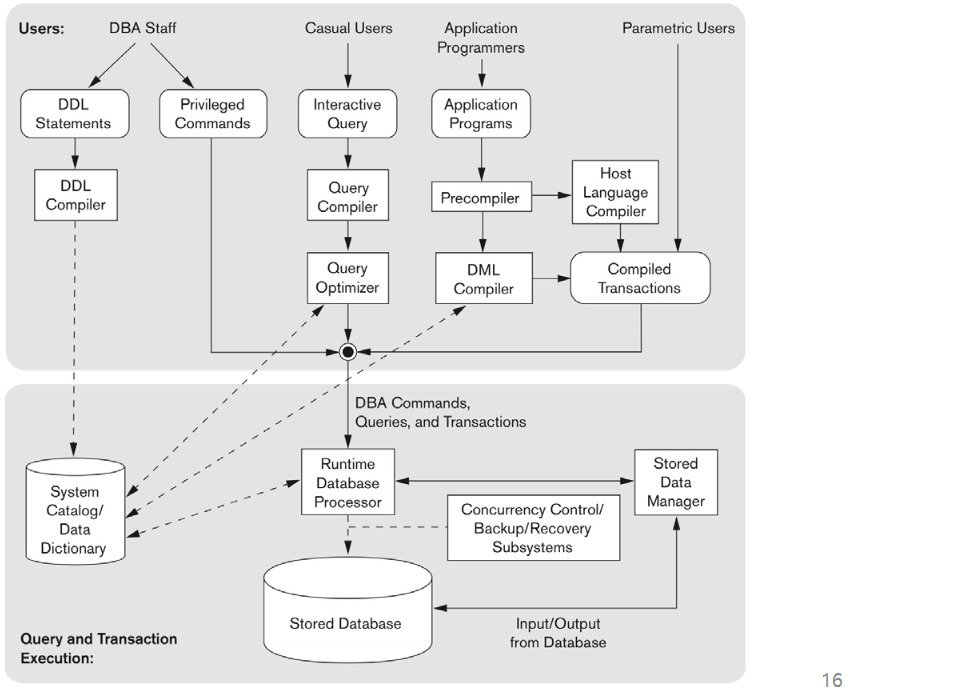
- DDL compiler : 스키마 정의를 처리하고 DBMS catalog 에 저장한다. (세팅 작업)
- Query compiler : 쿼리를 분석하고 파싱하여 internal form 으로 컴파일한다.
-
Query optimizer : 조인을 하거나 쿼리 알고리즘을 짤 때 가장 최적의 것을 선택하게 한다. System catalog 의 정보를 기반으로 선택한다. Executable code 를 생성해 낸다.
- Pre-compiler : 어플리케이션 프로그램에서 DML 명령어를 추출해낸다.
- DML compiler : DML 명령어를 받아서 데이터베이스 접근을 위해 object code 를 생성해 낸다.
- Host language compiler : 프로그램의 나머지 부분을 받는다.
- Run-time database processor : runtime 에서 데이터베이스에 접근한다. R/W operation 을 수행하며 stored data manager 를 요청한다. 통계를 가지고 system catalog 를 업데이트한다. Privileged Commands, executable query plans, canned transactions with runtime parameters 를 실행한다.
-
Stored data manager : 디스크(데이터베이스 & catalog) 접근을 제어하고, 메모리 버퍼나 데이터 전송 조절 등의 OS I/O를 사용한다.
-
Concurrency control and backup and recovery systems
Transaction management 를 control 한다.
- Database System Utilites : loading (파일을 데이터베이스로 넣는것, 변환), backup, database storage reorganization, performance monitoring
Structure of a DBMS
대표적인 DBMS는 layered architecture를 가진다. 어떤 모습은 concurrency control 과 recovery components 를 보여지 않는다.
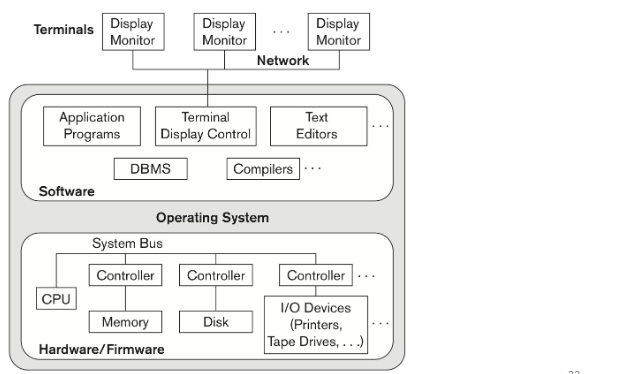
Basic Client/Server architectures
모든 어플리케이션이 하나의 OS에 존재하며 서버는 하나밖에 없다.
Two-Tier Client/Server Architectures
분업화된 구조를 갖는다.
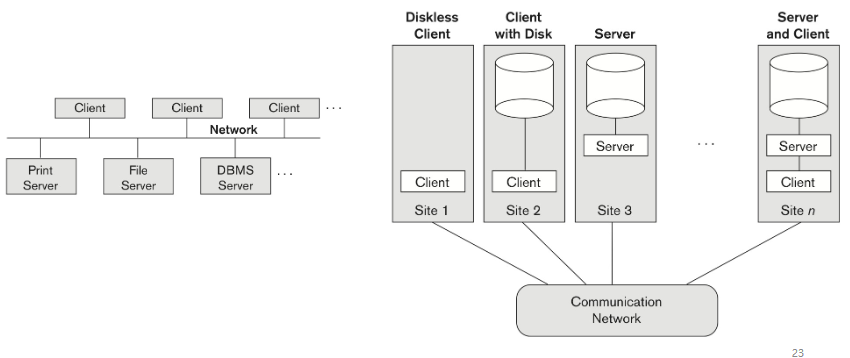
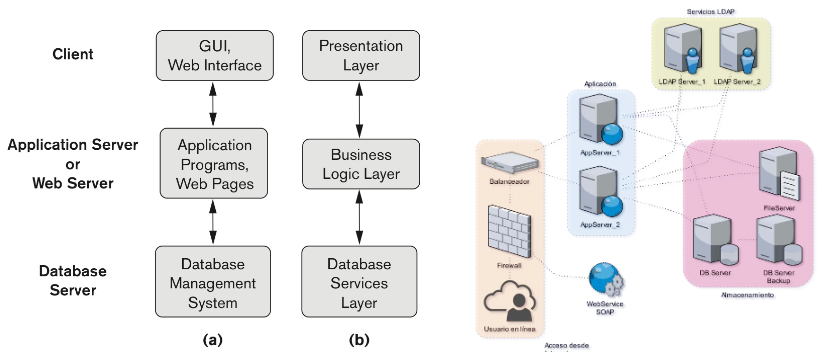
Three-Tier and n-Tier Architectures
최근 가장 많이 사용되는 방법이다.
DBMS의 분류
-
데이터 모델 분류 : 관계형, 네트워크형, 계층형, 객체지향형
-
사용자 수 : single-user system, multiuser system(concurrent suers)
-
사이트 수 : 중앙 집중식, 분산 DBMS (homogeneous DDBMSs, heterogeneous DDBMSs)
homogeneous DDBMSs : 모든 사이트가 동일한 DBMS 사용
heterogeneous DDBMSs : 사이트마다 다른 DBMS 사용
-
목적 : general-purpose DBMS, special-purpose DBMS
Databse Design
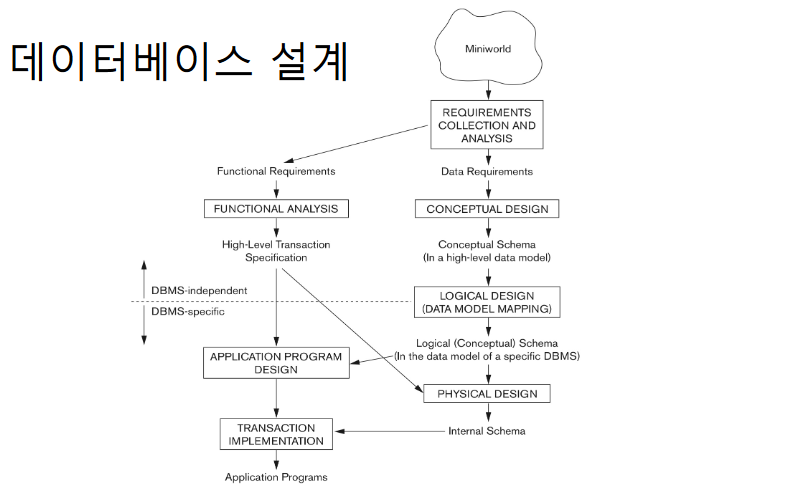
-
Requirements Collection and Analysis
DB 사용자의 요구를 수집하고 분석한다. 그리고 DB requirements 를 정리한다.
Data requirements : 어떤 데이터가 저장되어야 하는가
Functional requirements : 데이터를 어떻게 활용할 것인가(조회,삭제,삽입,갱신)
-
Conceptual Design
모든 data requirement들을 종합하여 high-level data model(high-level conceptual schema) 로 넘긴다.
Entity type, relationship, constraints 를 고려하되 저장에 대한 고려는 하지 않는다.
비전문 사용자들과의 상호작용을 위함이다.
Conceptual Schema 가 생성된다.
-
Functional Analysis
Functional requirements 를 high-level transaction 으로 넘긴다.
내가 만든 설계에 functional requirements를 적용할 수 있는지 확인한다.
개념적으로 이해하기 쉬운 트랜젝션으로 변환해 놓는다.
-
Logical Design (Data Model Mapping)
상용 DBMS를 사용해서 데이터베이스를 구현한다.
상용 DBMS는 일반적으로 구현 데이터 모델로 데이터를 표현한다.
Conceptual schema 에서 implementation data model 로의 mapping 이 필요하다.
-
Physical Design
내부저장 구조와 access path 를 설정한다.
Internal Schema 가 생성된다.
-
Application Programs Design
high-level transaction 을 사용해서 만든다.
Entity-Relationship Model
광범위하게 사용되는 개념적 데이터 모델(conceptual data model)로 DB 사용자가 이해하는 데이터베이스의 구조이다. 여기에는 개체(entity), 속성(attribute), 관계(relationship) 이 있다.
- Entity : 실세계에서 물리적 또는 개념적으로 존재하는 것이다. Entity 는 Attribute 값들의 집합으로 표현된다. 기본적으로 ER-diagram 에서 원으로 표기된다.
- Attribute : Entity 의 성질(속성)을 의미한다.
**Attribute 의 형태 **
-
Simple(atomic) attribute : 나눌수 없는 속성 ex) 나이
-
Composite attribute : 여러개의 속성으로 세분화 될 수 있는 속성 ex) 주소
( ) : composite attribute notation
-
Single-valued attribute : 각 entity당 오직 한개의 값만 갖는 속성 ex) 주민번호
-
Multi-value attribute : 한개 이상의 값을 가질 수 있는 속성 ex) 좋아하는 색
{ } : multi-value attribute notation
-
Stored attribute : 속성값이 DB에 저장된 것
-
Derived attribute : 다른 속성값으로 유된 것
Null value 의 종류
- Special value : 해당하는 속성에 표현될 수 없기 때문에 null 인 값
- Not Known : 속성값이 있지만 모르거나 존재 자체를 모르는 null 인 값
Entity Types, Entity Sets, Keys, and Value Sets
- Entity types : intension이라고도 부르며 스키마에 해당한다. 동일한 속성을 갖는 entity 의 구조를 정의한다.
- Entity Sets : extension 이라고도 부르며 인스턴스에 해당한다. Entity set에서 특정 entity를 찾기 위한 key attribute가 존재한다. 각 attribute들은 고유의 Value Set(Domain)을 가짐. ER diagram 에서 직사각형으로 표현이 된다.
- Key attribute : entity와 1:1관계를 가진다. 다수가 될 수도 있다. composite attribute로도 가능하지만 minimal 해야 한다.
- Key Constraint : 데이터의 제약조건, entity간에 unique하다
- Value sets (domain of an Attribute) : 모든 속성값은 domain을 가진다.
- single-valued attribute : 하나의 값만을 가지는 속성
- multi-valued attribute : set value ex) {1,2,3,4}
- composite attribute : 모든 경우의 곱으로 표현된다.
Initial Conceptual Design of Company Database
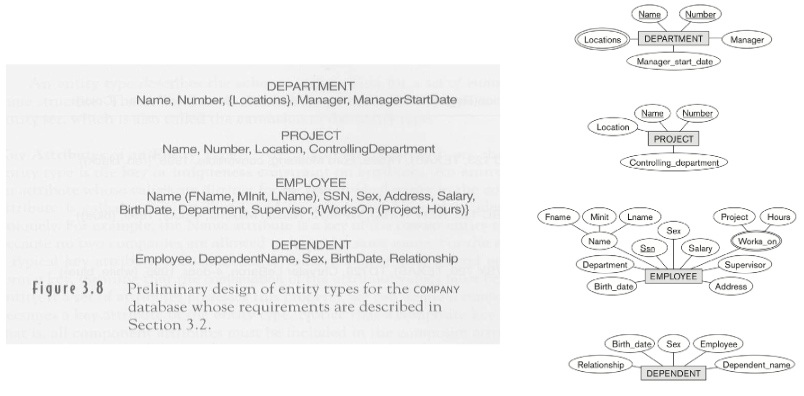
-
부서(DEPARTMENT) 는 Name과 Number를 key attribute로 가지고, Manager와 Manager_start_date를 가진다. 위치(location)은 multi-value attribute 이다.
회사는 부서들로 구성된다. 부서마다 각각 유일한 이름과 번호를 갖고 부서를 관리하는 부서장이 존재한다. 모든 부서장들에 대해서 부서장직의 시작날짜 를 기록한다. 또한 한 부서는 여러 군데 있을 수 있다.
-
과제(PROJECT) 는 Name 과 Number를 key attribute로 가지고, loaction과 controlling department 를 가진다.
각 부서는 여러 개의 과제를 수행하고, 각 과제는 유일한 이름과 번호를 가지 며 한 위치에 있다.
-
직원(Employee)는 고유한 속성들을 저장하고 Works_on 이라는 multi-value 를 통해 여러가지 과제 수행을 알려준다.
모든 직원의 이름, 주민등록번호, 주소, 월급, 성별, 생일을 저장한다. 각 직원 은 한 부서에 배정되지만, 여러 개의 과제에도 수행할 수 있다. 이때 과제는 꼭 자신이 속한 부서에서 관리 하는 과제일 필요는 없다. 각 직원이 과제 당 일하는 시간을 기록하고, 각 직원의 관리자를 기록한다.
보험을 위해서 각 직원 별 모든 가족 사항(이름,성별,생일,직원과의 관계)을 기록한다.
-
Dependent 는 관계만을 기록하고 key attribute가 없다.
-
Relationship between entity types (연관관계)
- 부서 <-> 직원
- 직원의 속성으로 부서를 본다(domain : all department)
- 부서의 속성으로 직원를 본다(domain : all employees)
-
Relationship Set : 여러개의 세트를 포함한다(비슷한 관계들의 모임)
-
Relationship Type : Entity Type 끼리의 관계로 말한다. ex) 직원 <-> 부서
Relationship
두개 이상의 entity들 사이의 관계를 의미한다.
- Relationship Instance : 어떤 하나의 관계
- Relationship Set : 비슷한 relationship 들의 세트. 하나의 n-ary relationship set R 은 n 개의 entity set 과 관계가 있다.
-
Relationship Type R : Relationship instance 들의 set 을 정의한다. n 개의 entity type E1,E2,…,En 간의 결합 집합이 R 이다. 이때 E1,E2 등은 R에 participate 한다고 한다.
- Degree : relationship type 에서 참여하는 entity type의 개수
- Role Name : relationship 에서의 entity type 의 역할이며 대부분 entity 이름으로 표현한다.
- Recursive relationship : 하나의 relation 에 같은 entity 가 묶여있는 경우 서로 recursive 하다.
Constraints on Relationship Types
Relationship에 미니월드의 constraints 를 표현한다.
구조적인 제약조건(structural constraints)로 표현한다.
-
Cardinality ratio : relationship instance 에 참여할 수 있는 entity 의 최대 개수를 나타내는 것이다.
1:1, 1:N, M:N 등이 있다.
-
Participation : relationship type 을 통해 다른 entity 와 연결된 entity 의 존재를 의미한다.
Total participation (existence dependency) 은 항상 하나 이상의 entity 와 관계가 있다는 것을 의미하며 ER diagram 에서 두줄로 표현한다.
Partial participation 은 일부만이 관계를 형성한다는 것을 의미하며 ER diagram 에서 한줄로 표현한다.
ex) 모든 department 가 manager 가 있어야 한다면 manage relation에 department 는 total participation 이 걸려야 한다.
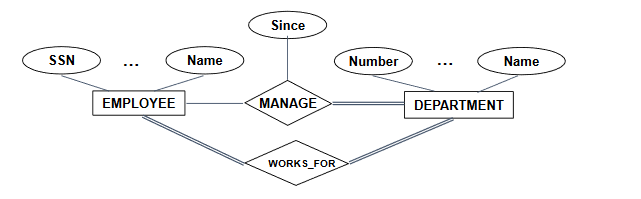
- Weak entity : 스스로 내가 가진 entity를 구분할 수는 없으나 속성값들의 조합을 보고 구분할 수 있는 entity. 스스로는 identified 될 수 없으며 owner entity 의 primary key 를 통해 구별될 수 있다. Weak entity set 은 identifying relationship set 에 항상 total participation 되어야 한다.
- Owner entity : weak entity의 일부 속성과 조합을 통해 identify 가능하게 해준다. Owner entity 와 weak entity 는 항상 1:N 의 관계를 가져야 한다.
- Partial key : 동일한 owner entity와 연결되어 entity를 유일하게 찾는 key. ER diagram 에서 dot line으로 표현한다.
Attribute migration
- 1:1 - 어느쪽으로든 옮겨서 표현해도 된다.
- 1:N - N 쪽으로 옮겨서 표현해도 된다.
- M:N - multi-value 로 표현하기 보다는 relation 으로 표기하는 것이 좋다.
Alternative notation for sturctural constraint
entity E <- (min, max) -> relationship type R 으로 표현할 때 min = 0 이면 partial participation 이고, min > 0 이면 total participation 이다.
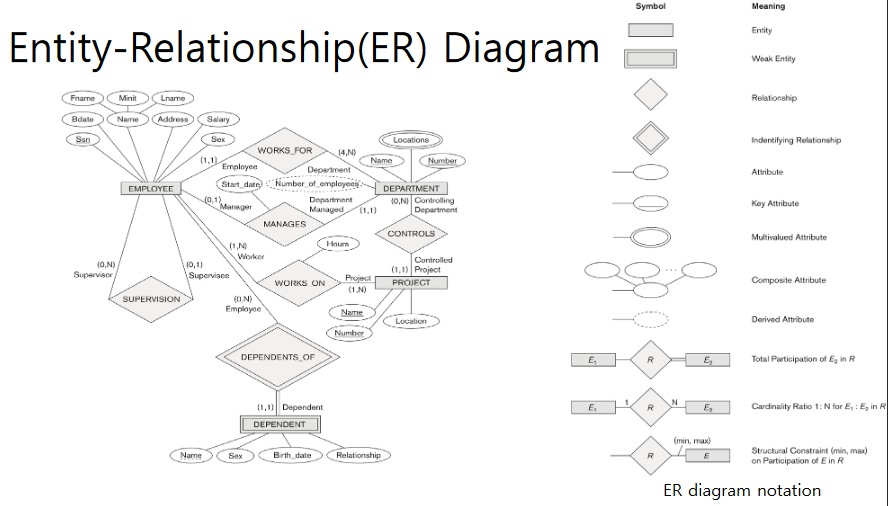
Naming convention
스키마 요소 이름에서 entity type 은 단수로 사용하고, entity type 과 relationship type 은 대문자로 작성한다. Attribute 이름은 첫문자만 대문자로 작성한다. Role name 은 소문자로 작성한다.
entity type name 은 명사, relationship type name 은 동사, attribute name 은 entity type name 을 묘사하는 명사여야 한다.
Entity vs Attribute
어떤 속성을 속성인 채 남겨 두어야 할까 아니면 entity 로 만들어야 할까?
만약 이 속성이 여러개로 나타날 수 도 있다면 multi-valued atrribute 로 만들고, 이 속성의 세부적인 속성들이 이용될 수도 있다면 composite attribute 로 만든다.
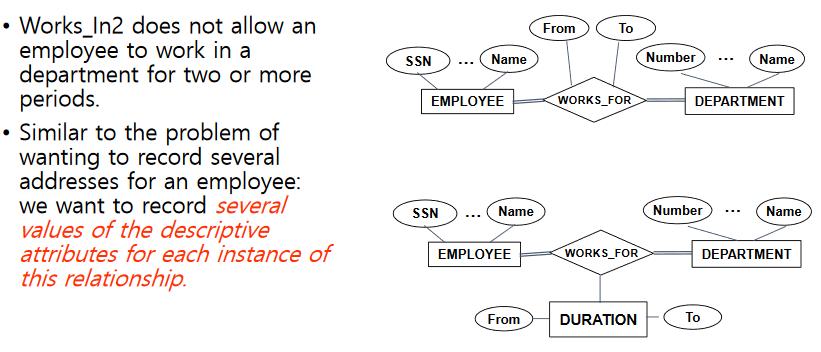
- 그림 1 처럼 Employee 가 Department 에서 일한시간(works_for from to) 을 적을때는 원래것을 지우거나, 생성하지 못하거나 constraint 가 걸려버린다.
- 그림 2 처럼 생성하면 Duration(entity)을 주어 복수의 relation을 생성할 수 있게 한다. (옛 data를 보존할 수 있다)
Entity vs Relationship
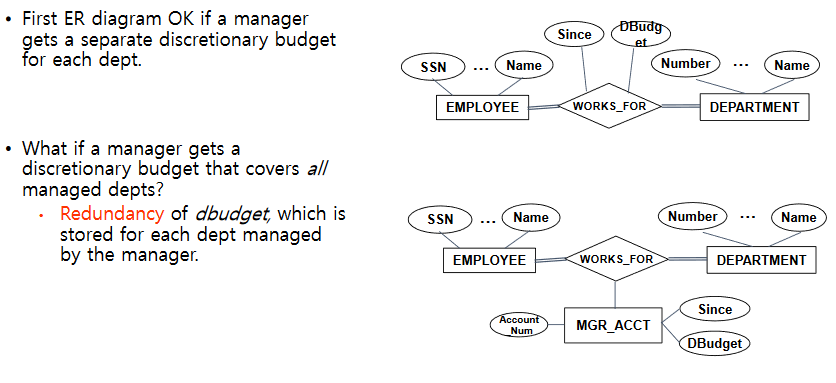
- Employee가 어떤 Deparment의 매니저인데 언제부터 얼마까지 사용할 수 있는가에 대한 예시인데, 부서가 다르다면 다른 relation으로 나타나므로 문제가 되지 않는다. 다만 예산이 relationship으로 관리가 되면 갱신될때마다 모든 relation을 갱신해 주어야 한다.
- 계좌 entity 를 생성해 주면 위의 문제가 해결된다.
Binary vs. Ternary Relationships
어떤것을 binary 로 ternary로 구현해야하는가?
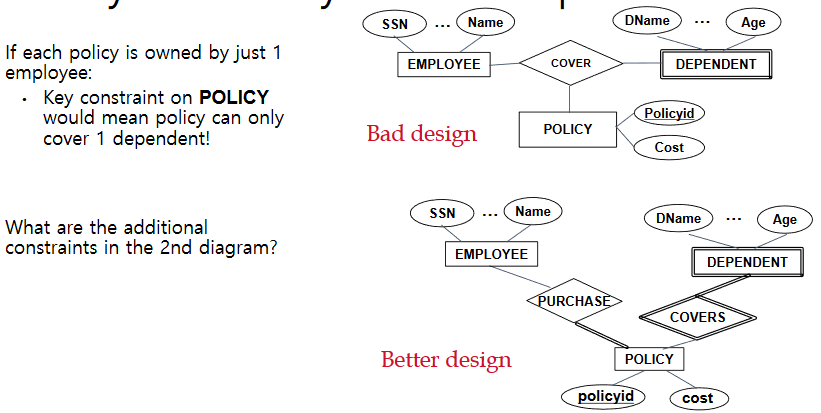
- 직원에게 가족이 있는데 직원 가족의 보험 정책이 Policy 객체이다. 단 모든 policy는 한명의 employee에 의해 관리가 된다. 그러므로 여러명의 부양가족에 여러개의 policy를 적용할 수 없다.
- Dependent를 weak entity로 표현하면 해결된다. employee 와 policy 관계가 1:N 이 되며 또한 policy 와 dependent 의 관계가 1:N 이 되므로 한명의 employee 가 자신의 부양가족들을 하나의 policy 로 관리할 수 있다.
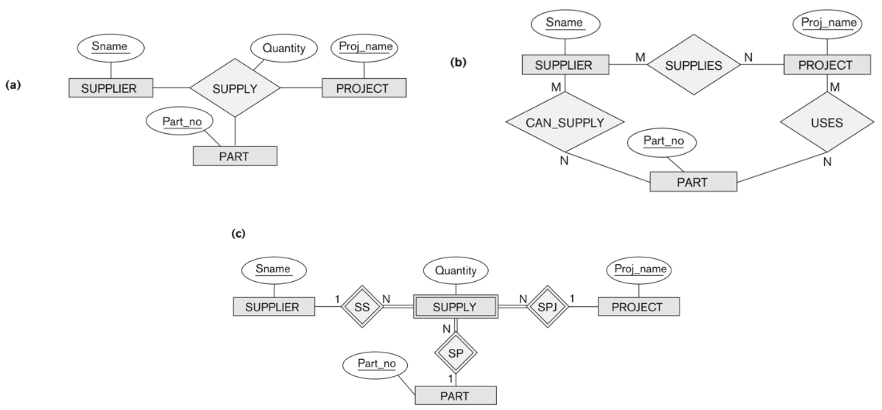
S 는 P 를 제공하고, D 는 S 가 P 를 제공하는 것을 허락하는 역할을 한다. 어떻게 Quantity 를 저장하고 binary relationship 으로 나타낼 수 있을까?
(a) 는 ternary 로 나타낸 모습이다.
(a) 의 예시를 바꾼 (b)는 모호하다. Supplier 가 Project에 연결되는지 알 수 없다. 왜냐하면 Part 와 Supplier 의 관계와 Project 와 Part 의 관계가 같지 않고, Supplier 또한 Project 에 연결되는지 알 수 없기 때문이다.
만약 꼭 binary로 만들어야겠다면 weak entity로 만들어서 (c)처럼 만들 수 있다.
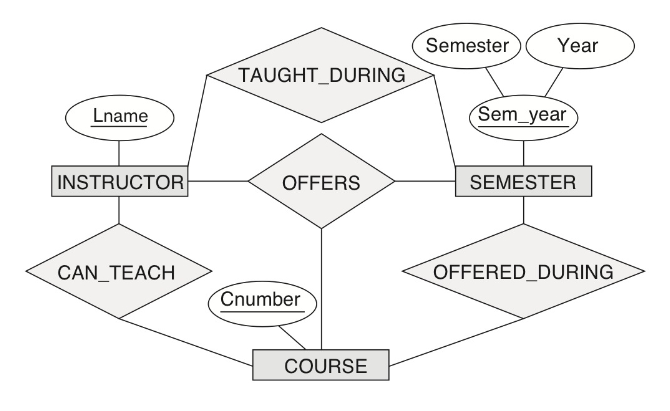
위의 그림에도 마찬가지로 위의 (b)와 같은 모호함이 나타난다.
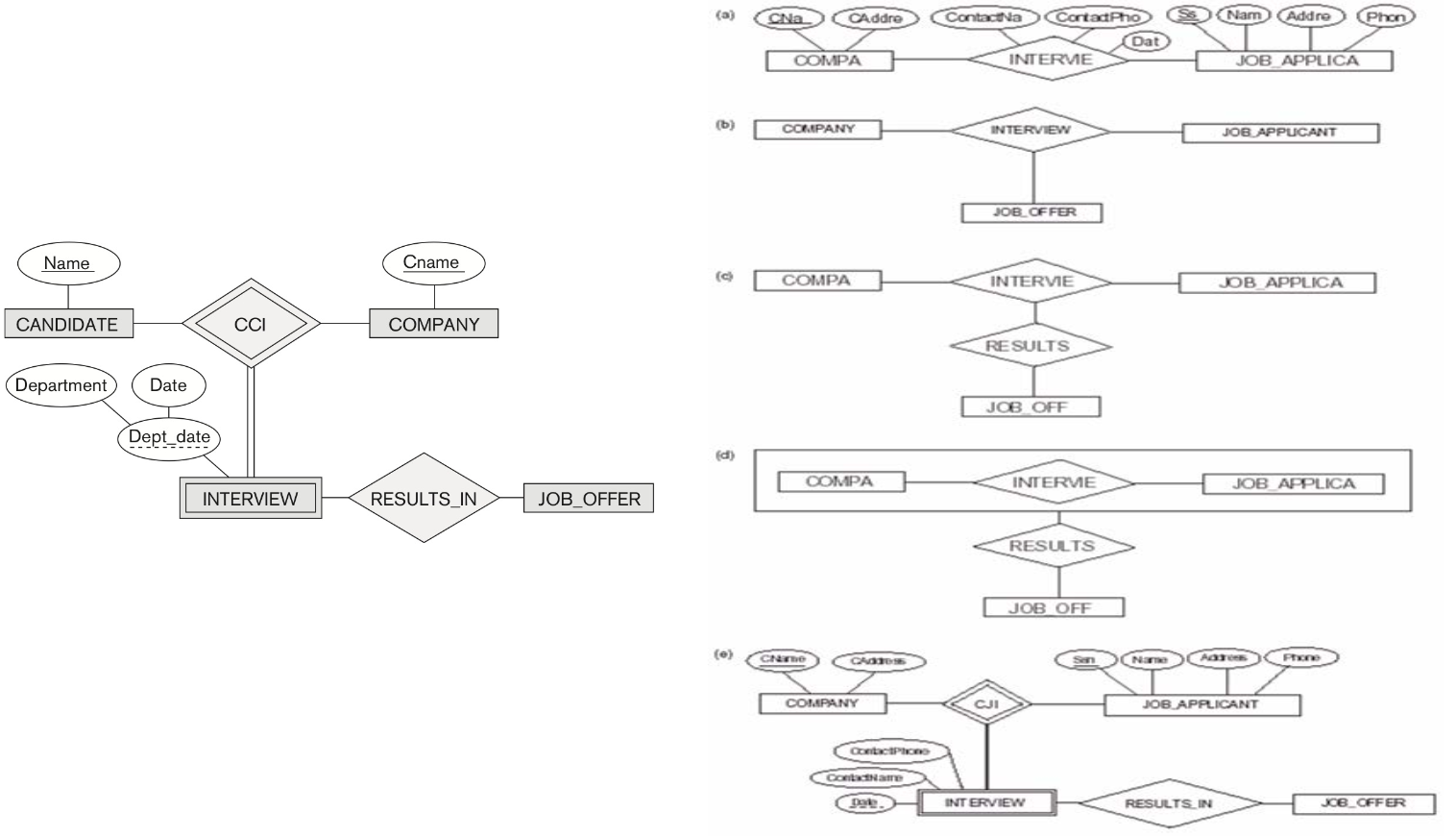
(b)는 JOB_OFFER가 없을때는 감안하지 않는다.
(c) 는 틀린 모양.
(e) 는 어떤 회사에 누군가 지원을 했다면 interview에 저장하고 이전 지원 기록들도 남겨 둘 수 있다. 또한 그 인터뷰가 Job_offer에 의해서 일어난 것도 알 수 있다.
이러한 개념을 aggregation 이라 한다.
Summary of Conceptual Design
Conceptual design 은 requirements analysis 가 필요하다. 그리고 저장될 데이터의 high-level description 을 만들어 낸다.
주로 ER 모델로 표현이 되는데 entity, relationship, attribute, weak entities, ISA hierarchies, aggregation 등으로 구성된다.
몇가지 무결성 제약조건들이 표현될 수 있는데, key constraints, participation constraints, foreign key constraints 등이 표현될 수 있다.(relationship set 의 definition 에서) 그러나 몇가지 constraints 들은 ER 모델에서 표현 될 수 없다.
ER design은 주관적이여서 많은 방법이 있을 수 있다. FD information 과 normalization 은 design 하는데 유용한 기술이 될 수 있다.
Comments