Database Relational Model
ISA (is-a) Hierarchies
만약 A ISA B 라고 한다면, 모든 A entity 는 B entity 로서 간주된다.
ex) Employees ISA Contract_Employees
Superclass(A) 의 속성들을 subclass(B) 에게 적용시키기(물려주기) 위해 사용한다.
Relationship 에서 entity 를 identify 하기 위해 사용한다.
Superclass, Subclass
class는 type이다. type은 entity의 세트다. 그러므로 class는 entity 의 세트다.
만약 A 가 B 의 superclass 라면 B의 속성은 A에 존재하지만, A의 속성은 B에 존재하지 않는다.
이때 A 가 B 의 superclass 이고 B 는 A 의 subclass 이다.
Attribute inheritance
만약 B 가 A 의 속성을 상속받으면 B 에는 B 고유의 속성과 A 의 속성이 함께 존재한다.
Specialization
Superclass에 대해 이루어진 특정한 관계들의 superclass-subclass relation들의 집합이 specialization이다.
Superclass G 와 구별되는 특정 속성을 가지고 있는 것을 기초로 한다. 먼저 subclass 들 중 다른 entity type 과 다른 additional specific attribute 가 있거나 relationship type 이 있는 경우 그 specific attribute 를 표기해 준다. 즉 어떤 superclass에 대해 특수한 서브셋들을 뽑아내고, 특수한 속성을 달고, 특수한 relation이 필요하다면 단다.
Generalization
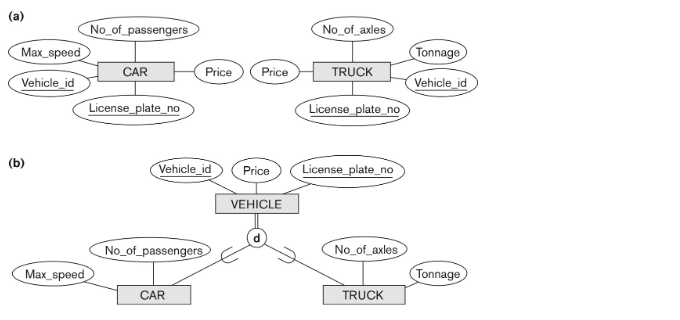
Specialization 의 역방향으로, 공통 속성들을 합쳐서 특수 속성들만들 남겨놓는 방식이다.
Constraint on specialization/generalization
Predicate-defined subclass : 특수 속성값에 대해 constraint를 걸어 specialization을 하는 것이다.
ex) jobtype 을 가지고 constraint 를 걸 수 있다. [jobtype = secretary] 이때 jobtype 이 defining attribute 이고 secretary 가 attribute value 가 된다.
Attribute-defined specialization : 속성의 값을 가지고 specialization 을 할 수도 있다.

다이어그램에서 표현할 때 superclass 와 동그라미 사이에 defining attribute 를, 동그라미와 subclass 사이에 attribute value 를 표현한다.
User-defined subclass : defining attribute 와 attribute value 를 이용해서 자동으로 specialize 하지 않고 유저가 직접 정의해서 관리한다.
Disjoint constraints
- Disjoint : 동그라미가 그려진 d 는 복수의 subclass를 가질 수 없다는 것을 의미
- Overlap : 동그라미가 그려진 o 는 복수의 subclass를 가질 수 있다는 것을 의미
Completeness constraint
- Total specialization : 두줄은 무조건 어떤 subclass를 가져야 한다는 것을 의미
- Parital specialization : 아무 subclass를 가지지 않아도 된다.
Insertion & deletion rules for specialization/ generalization
- Superclass 의 entity 를 삭제할 때, 모든 subclass 로부터 자동으로 삭제가 된다
- Superclass 에 entity 를 추가할 때, 모든 predicate-defined subclass 에 (만약 defining predicate 를 만족하면) 자동으로 추가된다.
- Total specialization 일 때 superclass 에 entity 를 추가하면 적어도 하나의 subclass 에 자동으로 추가된다.
Specialization hierarchies & lattices
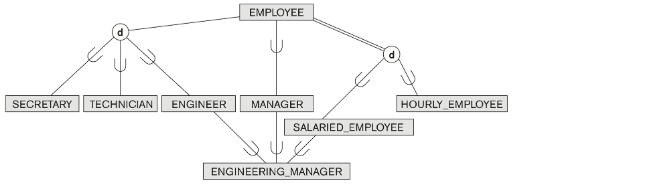
-
lattice : 서브클래스가 하나 이상의 클래스나 서브클래스를 갖는다.(multiple inheritance) 모든 superclass 들의 속성을 상속받는다.
여기서 lattice 는 engineering_manager. engineer, manager,salaried employee의 상속을 받는다.
-
hierarchy : 모든 서브클래스 서브클래스 관계가 싱글이다.(single inheritance)
Top-down vs Bottom-up conceptual design
위에서 아래로가는 specialization 은 top-down. 이것을 successive specialization 이라 한다.
아래서 위로가는 specialization 을 bottom-up. 이것을 successive generalization 이라 한다.
Union types
만약 superclass 들이 하나의 union 이라면 한번에 하나의 entity 속성만이 상속된다.
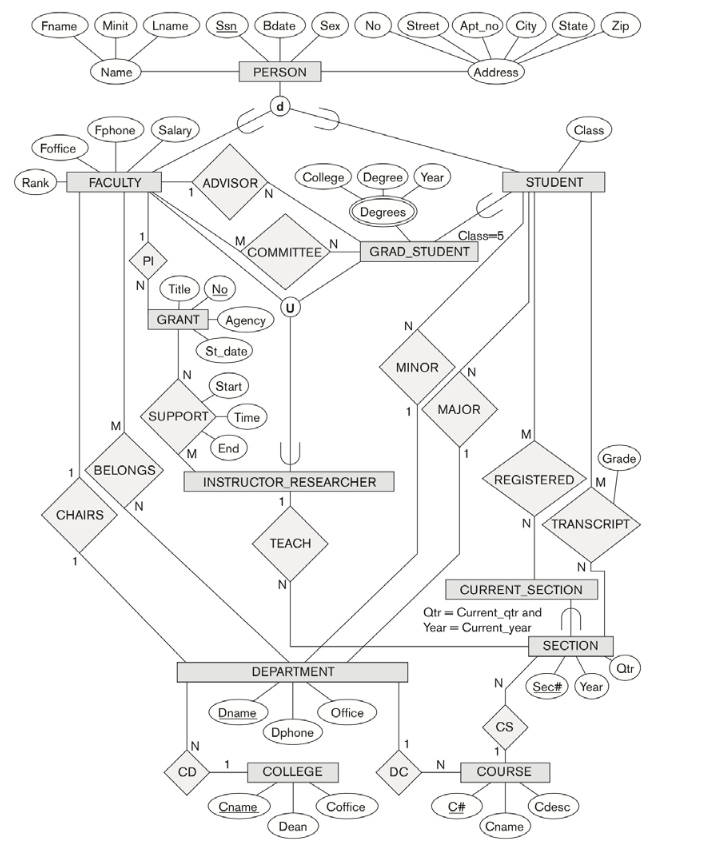
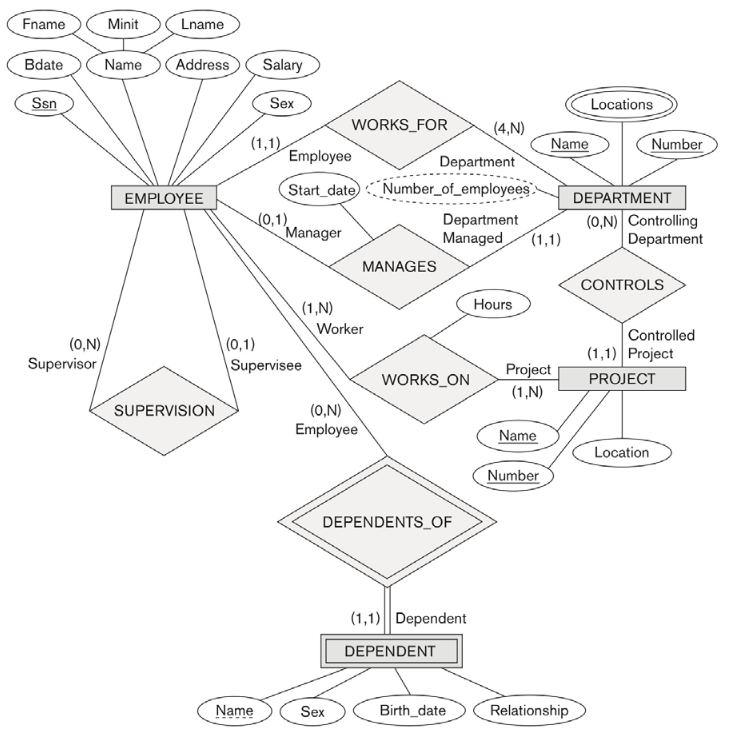
The Relational Data Model and Relational Database Constraints
어플리케이션 단에서 data를 제어하기에는 부하가 많이 걸리므로 database 모델에서 제어한다.
데이터를 수정할 때에도 간섭한다.
Domain, Tuples, Attributes, Relations
겉으로 보기에는 flat file과 relation은 비슷해 보인다.
relation이란 가지고 있는 정보를 수학적으로 정의하는것
- Tuple : relation의 각 row
- Attribute : relation의 각 column 속성
- Relation Name : relation의 이름
Relational Model Concepts
-
Domain : entity의 value set 과 비슷한 개념. 더이상 나누어지지 않는 단위들의 set
-
Relation Schema(intension) : relation의 이름과 relation의 속성들을 정의함
각각의 속성들은 Domain에 연결된다.
degree of a relation : 속성의 개수
domain of A1 = dom(A1)
relation intension = relation schema R
EX) R(A1,A2,A3,A4) 여기서 R은 relation name, A1,A2,A3,A4 는 R의 속성값
-
Relation state(extension) : relation state는 n개의 tuple이 있다.(degree 가 n 이므로)
하나의 튜플에는 relation schema의 속성들이 대응된다.
relation extension = relation instance r(R)
-
r(R) 이란 각각의 속성값들이 가질 수 있는 모든 경우의 수의 카테시안 곱의 서브셋이다.
-
Cardinality : 도메인 값이 가질 수 있는 경우의 수, 또는 현재 relation의 도메인 가지수
-
Current Relation State : 특정 시간의 relation state(instance)
relation 은 dynamic 하지만 relation schema 는 almost static 하다.
Relation의 특성
-
relation에서 tuple의 순서는 중요하지 않다. (no ordering)
파일에서는 physical ordering 이 존재한다.
-
하나의 tuple에서 속성들의 순서는 중요하다. (ordering)
-
Alternative definition 가능하다. (
, ) pair 만 맞으면 순서는 상관없다. -
Tuple의 value는 atomic value여야 한다.
composite/multi-valued attribute 는 불가능하다(first normal form)
relaxation : nested relation or non-first normal form
-
NULL value 는 여러가지 경우가 있을 수 있다.
-
Relation의 해석
Relation 이란 entity 나 entity 들 사이의 관계를 나타낸다.
Relation Schema 는 속성들의 정의를 나타낸다.
각각의 tuple 은 값(사실)을 나타낸다.
Relational Model Notation

Constraints
Inherent model-based (implicit) constraints
Schema-based (explicit) constraints
Application-based (semantic) constraints or business rules
Domain constraints : 속성 A의 도메인은 dom(A)로 표현되며 데이터 타입을 정의하고, 도메인 범위내에 값이 무조건 존재해야 한다. 또한 date 나 time 같은 format 형식도 가질 수 있다.
Key constraints : relation 에서 모든 tuple들은 key 에 의해서 구별되어야 한다. 이렇게 구별이 되는 속성들의 조합을 superkey 라고 한다. 모든 relation schema 는 적어도 한개 이상의 superkey 를 가지고 있으며 key 는 최소 superkey 의 하나이다. 이 후보 key 들이 candidate key 이고, primary key 는 candidate key 들 중에서 mini-world 에 의해 결정이 된다(DB designer 에 의해). 단순속성이나 적은 수의 속성으로 결정하는 것이 좋다. unique key 란 primary key 가 아닌 key를 의미한다.
Relational Database Schema
relational database 는 여러개의 relation 으로 구성이 되어 있으며 relational database schema S = {R1,R2..} 로 표현될 수 있다.(Ri : relation schema) relation schema 들과 integrity constraints 들의 세트로 이루어진다.
relational database instance DB 는 integrity constraint 를 만족하는 relation instance 의 집합이다
relational database = relational database schema + relational database state
Entity & Referential Integrity
Entity integrity constraint : primary key 는 null 값을 가질 수 없다.
Referential Integrity constraint : 한 relation 의 tuple 에서 다른 relation을 참조할 때는 항상 참조되는 tuple 이 존재해야 한다.
Foreign Key
참조되는 key 로서 FK 로 나타낸다. ex) dom(FK) = dom(PK)
FK 의 도메인과 참조하는 PK 의 도메인이 같아야 한다.(또는 포함되어야 한다)
semantic integrity constraint : 대부분의 DBMS에서 지원하지 않지만 mini-world 에서 작용하는 제약조건이다. 또는 DBMS에서 trigger 나 assertion 을 통해 관리가 가능하기도 하지만, 대부분은 application level 에서 관리한다.
functional dependency constraint : 특정 속성이 다른 속성을 제약하는 것이다.
Insert Operation
새로운 tuple 을 relation 에 추가하는 것이다.
constraint checking 은 domain constraint(값이 범위내에 있어야 한다), key constraint(키가 중복되지 않아야 한다), entity constraint(null 이 아니어야 한다), referential constraint(참조되는 tuple 이 있어야 한다) 를 한다.
제약조건에 걸리게 되면 reject insertion 하거나 유저와 상호작용해서 insertion 을 고친다.
Delete Operation
relation 에서 기존 tuple 을 제거한다.
constraint checking 은 referential integrity constraint 를 확인한다.(삭제될 tuple 이 다른 relation 에 의해 참조될때)
제약조건에 걸리게 되면 restrict 는 delete operation 을 reject 한다. 또 cascade 는 참조하는 모든 tuple 을 함께 삭제하는 것이고, set null(or default) 은 참조하는 값을 null로 바꾸는 것이다. 이때 만약 참조하는 속성이 key 이면 null 로 바꾸지 못한다.
Modify Operation
삭제하고 추가한다고 생각하면 된다.
Insert 와 delete 의 constraint 를 모두 포함한다.
Defining Relation
설계된 DB 를 DBMS 에서 정의하는 법이다.
Relational DBMS, Relational database schema, domain, relation 을 정의한다.
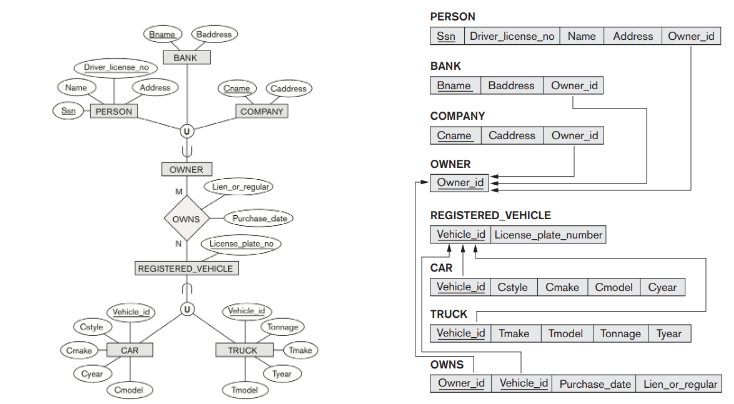
ER to Relational Mapping Algorithm
ER diagram 으로 RDB 를 디자인한다.
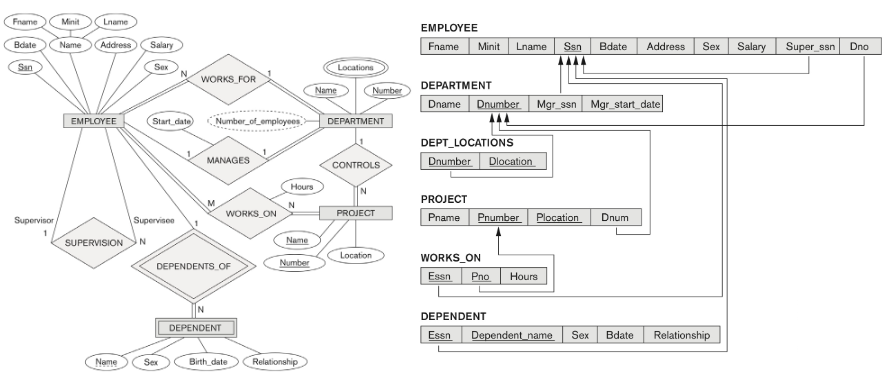
-
Step 1 : entity를 table로 변형한다.
- simple attribute는 그대로 테이블에 표현한다.
- 복합 속성들은 따로 나누어서 표현하거나 합쳐서 표현할 수 있다.
- entity 무결성 설정 (primary key 설정)
-
Step 2 : weak entity 설정
- key attribute 속성 세팅이 안되기 때문에 (owner key + partial key) 를 primary key로 설정한다. foreign key는 owner key가 된다. ex) DEPENDENT 의 Essn 이 foreign key 이다.(EMPLOYEE 의 PK Ssn)
-
Step 3 : 1대1 relationship
-

Manage relation 의 attribute Start_date 를 Department 에 붙인다.
- 속성을 뒤에 붙여버릴 수 있다. (ex예제 내용)
- 몽땅 붙여버릴 수도 있다. (다른 관계가 없을 고, total participation 일때)
-
-
Step 4 : 1대N relationship
-

N 쪽에 1쪽의 PK 를 FK 로 넣는다.(rename 해서)
-
-
Step 5 : N대M relationship
-

- S relation 에 각 entity(relation schema) 들의 primary key 들을 가져와서 S 의 primary key 로 지정한다.
- S relation 에 각 entity(relation schema) 들의 primary key 들을 가져와서 S 의 foreign key 로 지정한다.
-
-
Step 6 : multi-valued 속성 표현
-

- 따로 table을 만든다.
- owner 의 primary key 를 가져오고 multi-valued 속성을 primary key 로 지정한다.
- 가져온 owner 의 primary key 가 foreign key 가 된다.
-
-
Step 7 : n-ary relationship
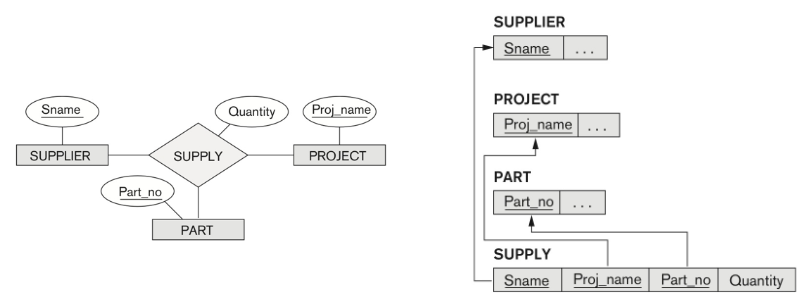
-

- 새로 table을 만드는데 연결된 entity 의 primary key들을 가져와서 만든다.
- 가져온 primary key 들이 FK 가 된다. 그 중 max=1 관계인 entity type 의 PK 를 PK 로 설정한다.
Mapping transition
Relational model does not represents explicitly
multi-valued 속성이나, 두 tuple 이 관계를 가지고 있다는 것을 한눈에 표현하지는 않는다.
-
1:1 and 1:N relationship type —> one join 연결
-
M:N relationship type —> two join 연결

-
n-ary relationship type —> n join 연결
-
multi-value 속성 —> one join 연결

EER to Relational Mapping Algorithm
Step 8 : Specialization / generalization
-
1번 방법 (ISA 관계)
-
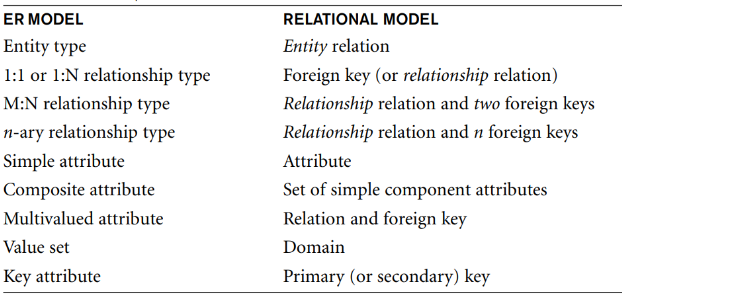
- Superclass 의 primary key 는 기존의 key 와 같다.
- Subclass 들의 FK 는 모두 superclass 의 PK 와 같다.
- Relation 으로 표현할 때는 disjoint/overlapping, total/partial 이 중요하지 않다.
-
-
2번 방법

- Superclass 의 table 을 생성하지 않는다. ex) VEHICLE table 이 존재하지 않는다.
- Subclass 에 VEHICLE superclass 의 모든 속성들이 포함되어 나타난다.
- 단 partial 인 경우에는 해당되지 않고, total participation 일 때만 가능하다. (아무쪽에도 속하지 않는 속성이 존재하게 되므로)
- 반드시 disjoint 해야한다. (중복되어 부하가 걸릴 수 있다.)
MUST BE TOTAL and DISJOINT
-
3번 방법

- 모든 subclass 의 고유 특성을 다 superclass 에 합치고 필요한 부분만 정보를 넣고 나머지는 null 로 유지한다. job_type을 가지고 어떤 subclass 내용인지 알 수 있다.
- 반드시 disjoint 일 때에만 가능하다. relation 의 속성값은 항상 atomic value 여야 하므로 overlapping 인 경우 job_type 이 multi-value 가 되므로 불가능하다. (단 모든 경우의 수의 job_type value 를 만들어 주면 가능하긴 하다. 이 경우에는 null value 가 많아지는 단점이 생기지만, join이 적게 들어가는 장점이 있다.)
- 만약 partial 이라면 job_type 은 null 이 된다.
MUST BE DISJOINT
-
4번 방법
-
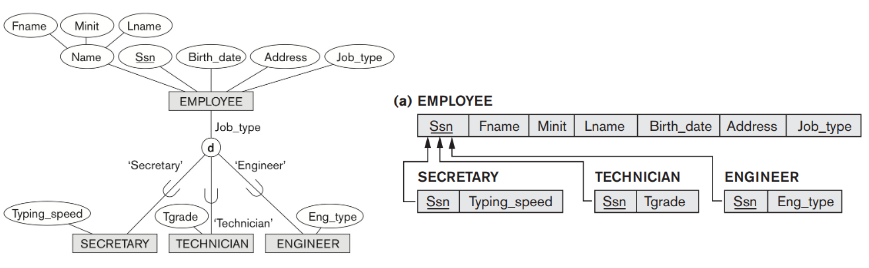
-
3번처럼 합치되 job_type 같은 구별 속성이 존재하지 않는다면 뒤에 각각의 subclass 에 대한 Flag를 달아서 사용할 수 있다. overlapping 까지 구현할 수 있다. ex) Mflag, Pflag
-
예제
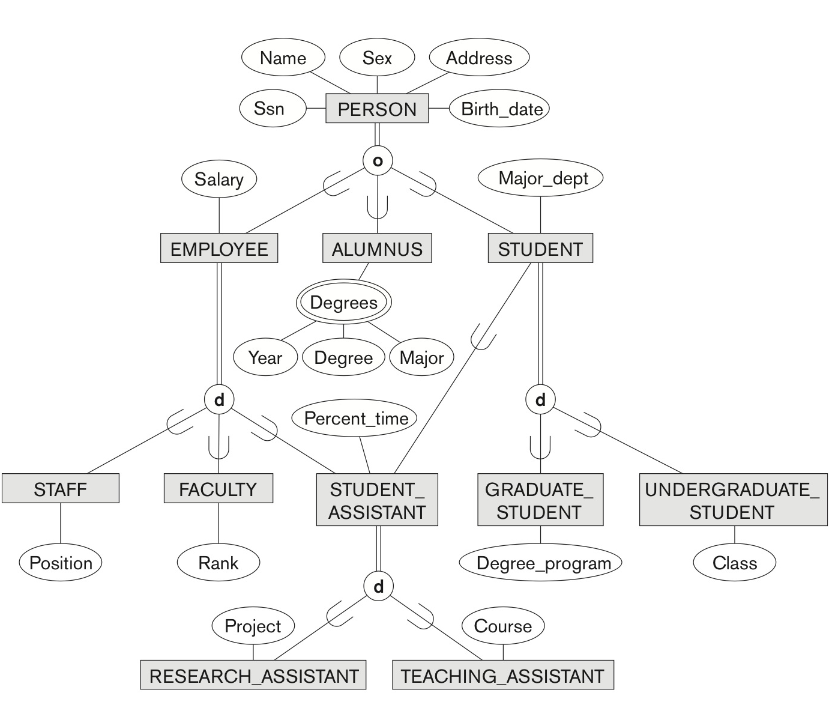
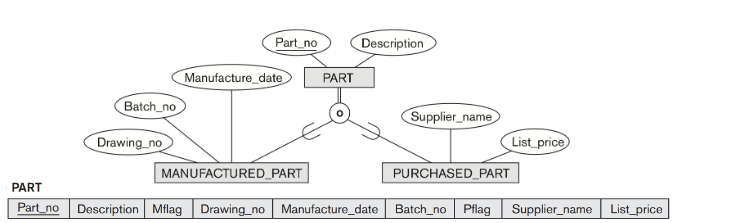
PERSON 은 1번 방법을 사용했다 (superclass 있음, subclass 있음)
EMPLOYEE 는 3번 방법을 사용했다 (모두다 superclass 에 합치되 employee_type 으로 구별한다)
STUDENT_ASSISTANT 는 4번 방법을 사용했다 (모두다 superclass 에 합치되 flag 을 주었다)
STUDENT 는 4번 방법을 사용했다 (모두다 superclass 에 합치되 flag 을 주었다)
EER to Relational Mapping Algorithm
Step 9 : Mapping of union types(Categories)
각각의 superclass 의 pk 가 다르기 때문에 subclass 에서 사용할 수가 없다. 따라서 superclass 에 subclass 의 key 를 포함하게 하고 이것을 surrogate key 라고 한다.
SQL 이 필요한 이유나 정의에 대해서 이해하라
SQL (Structured Query Language)
Declarative language 로서 what to do 에 관해 질의한다.(procedural language 는 how to execute 를 지시하고 Relational Algebra & Relational Calculus 등이 있다). DBMS 에 의해 실행순서가 조절되고 최적화 된다.
Relation => table
Tuple => row
Attribute => column
SEQUEL (Structured English Query Language)
70년대에 IBM에서 개발되었고, 회사들 마다 standard 한 기준이 필요해져서 만들어졌다.
SQL schema
relation schema 를 database system 에 집어넣기 위해 필요하다
동일한 데이터베이스에 있는 table 및 기타 construct 로 구성되며 schema name + authorization identifier + descriptors for tables, constraints, view, domains, and other constructs 로 구성된다. 여기서 authorization identifier 는 DB 관리자이다.
CREATE SCHEMA company AUTHORIZATION 'test';
Catalog
스키마의 집합체이다. 도메인 정의 같은 요소들을 공유한다. Integrity constraint 들을 공유한다.
INFORMATION_SCHEMA
스키마에 대한 정보를 저장하고, table 이 어떤것이 있고, 각각의 속성이 어떤 것이 있는지 등등을 저장한다. 제약조건에 대한 정보 및 도메인 정의도 같은 스키마 안에서 공유된다.
oracle 에서는 meta-data 라고 부르기도 한다.
Create Table
relation 이름, 속성이름, constraints 등이 포함된다
CREATE TABLE COMPANY.EMPLOYEE;
Data type
어떤 데이터 타입인지 설정한다.
고정길이(CHAR(n))와 가변길이(VARCHAR(n),CLOB) 도 가능하다. 가변길이는 디스크 용량을 압축해서 사용할 수 있다. CLOB 이란 character large object 로 4000자 이상인 경우이다. byte 단위에서는 BLOB을 사용한다. (BLOB은 주로 사진파일이나 문서파일을 적용)
interval data type 은 시간의 차이를 의미한다.
속성 데이터형을 정의할 수 있다. 마치 함수처럼
CREATE DOMAIN SSN_TYPE AS CHAR(9);
Specifying Constraints in SQL

-
NOT NULL constraint : primary key 또는 다른 null 값을 허용하지 않는다.
-
default value : 초기값을 설정한다. DEFAULT
-
base table : create table로 선언된 relation 의 모습
-
virtual table : view 로 보여주게끔 만든다
-
특정 referenced 된 tuple 을 삭제하려 할 때 기본값은 reject 이다. 같이 사라지게 하는것이 cascade, referencing tuple 의 foreign key를 null 이나 기본값으로 바꾸는 것이 SET NULL/SET DEFAULT 이다.

-
DROP SCHEMA/DROP TABLE (스키마나 테이블 삭제)
- RESTRICT : 스키마에 아무것도 없으면 삭제한다. 있으면 삭제하지 않는다.
-
ALTER TABLE
- 속성 추가, 속성 삭제, value 삭제 및 기본값 설정
Comments