Text Mining Introduction
텍스트 정보처리(Text mining)
구조화되지 않은 unstrutured data 로 부터 새로운 지식을 발견하는것이다.
텍스트 전처리
unstructured data → structured data
텍스트 마이닝
unstructured data 에 존재하는 pattern, trends, association 을 찾아내는 것
구조화 VS 비구조화
비구조화 데이터는 internal structure 가 있을수도 있지만, 미리 정의된 구조나 스키마는 존재하지 않는다. 그래서 non-relational db 인 nosql 에 저장을 하기도 한다.
Semi-structured data
Markup Language XML 이나 JSON 형태등이 있다.
정보를 구조화하고 계층화한다
XML JSON 은 간단하게 넘어감
정보처리과정
- 수행하고자 하는 목표 설정
- 데이터 수집
- 전처리
- 데이터클리닝
- 자연어 처리
- 데이터 탐색
- 데이터 분석
- 통계분석 : 회귀분석, 오차
- 기계분석
Text mining process
기존의 데이터 마이닝에서 다른 리소스를 가지고 전처리를 하는 부분이 추가되었다.
전처리의 과정이 굉장히 부각된다.
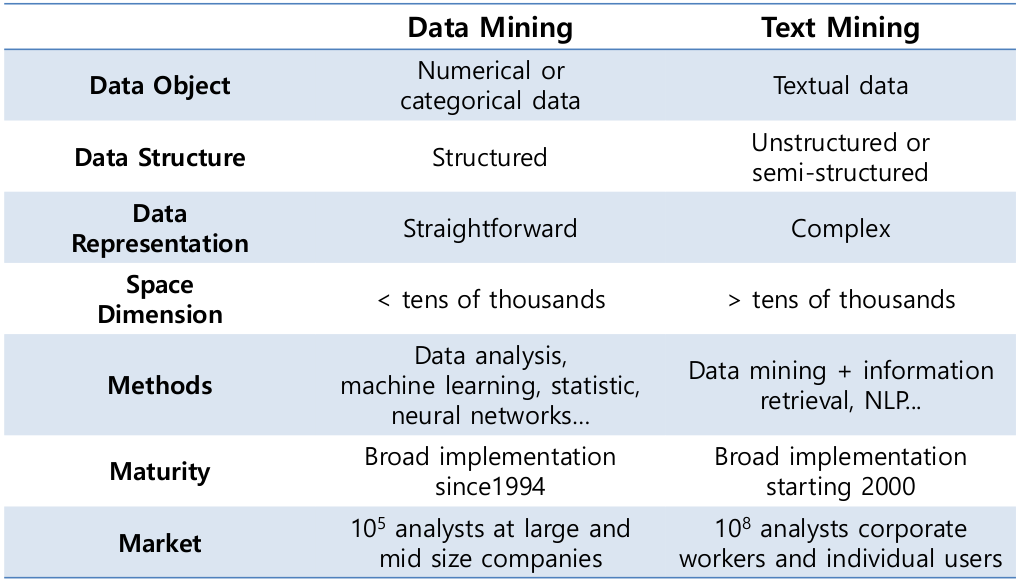
TM vs DM
TM vs DM in ML
수만개의 텍스트 중에서 뽑아내어 feature 를 만든다.
data mining 에서는 select feature 라고 부르며, text mining 에서는 extract feature 라고 부른다. Extract feature 는 select feature 에서 뽑아 낸다.
Structure of Text

문장 구조
어절은 Token 단위이다.
자연어 처리의 가장 중요한 이슈중 하나는 형태소의 분석이다.
POS : 품사를 분석하여 명사만 추출해 내는 것
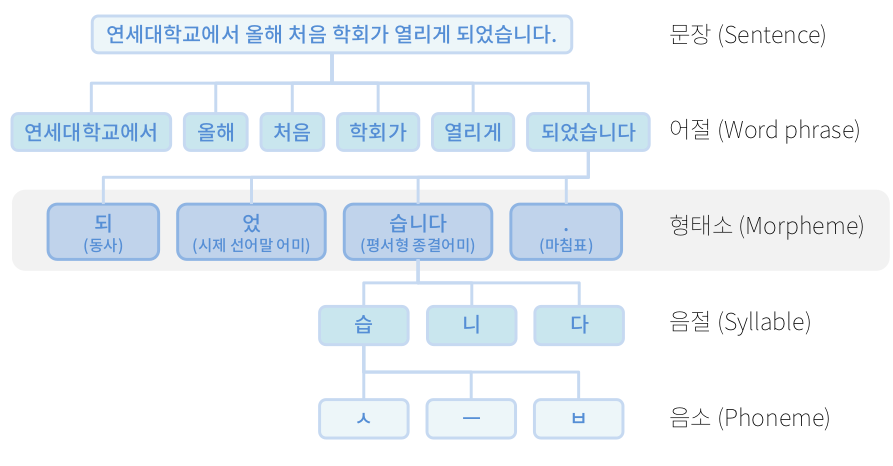
structure of sentence
Dependency Parse
의존 구문분석이라고 하며 동사구, 형용사구 등을 분석하는 과정이다.
Analyzing Text
NLP : Corpus → Document → Paragraph → Sentence → Token
- Token level
- Ontologies : 단어들 간의 계층구조, 관계가 반영된 것
- Inexact match : 자연어 처리단계에서 오타 및 문법적 변형을 찾는 것 (Edit distance)
- Regular Expression : 정규 표현식
Issues

수업 목표
텍스트 정보의 주요 특성을 이해하고 웹에서 텍스트 정보를 수집, 추출하여 파싱한다.
간단한 NLP 처리기법을 익히고 활용하며, Python 으로 텍스트 처리를 실습한다.
lemmatization : 원형 복원법
Comments